AI will not be magic. The instruments that generate essays or hyper-realistic movies from easy consumer prompts can solely accomplish that as a result of they’ve been educated on large information units. That information, after all, wants to come back from someplace, and that someplace is usually the stuff on the web that is been made and written by folks.
The web occurs to be fairly a big supply of knowledge and data. As of final yr, the online contained 149 zettabytes of knowledge. That is 149 million petabytes, or 1.49 trillion terabytes, or 149 trillion gigabytes, in any other case often known as a lot. Such a collective of textual, picture, visible, and audio-based information is irresistible to AI corporations that want extra information than ever to continue to grow and bettering their fashions.
So, AI bots scrape the worldwide net, hoovering up any and all information they will to higher their neural networks. Some corporations, seeing the enterprise potential, inked offers to promote their information to AI corporations, together with corporations like Reddit, the Related Press, and Vox Media. AI corporations do not essentially ask permission earlier than scraping information throughout the web, and, as such, many corporations have taken the alternative strategy, launching lawsuits in opposition to corporations like OpenAI, Google, and Anthropic. (Disclosure: Lifehacker’s dad or mum firm, Ziff Davis, filed a lawsuit in opposition to OpenAI in April, alleging it infringed Ziff Davis copyrights in coaching and working its AI programs.)
These lawsuits in all probability aren’t slowing down the AI vacuum machines. The truth is, the machines are in determined want of extra information: Final yr, researchers discovered that AI fashions have been working out of knowledge essential to proceed with the present fee of development. Some projections noticed the runway giving out someday in 2028, which, if true, offers only some years left for AI corporations to scrape the online for information. Whereas they will look to different information sources, like official offers or artificial information (information produced by AI), they want the web greater than ever.
When you have any presence on the web by any means, there is a good likelihood your information was sucked up by these AI bots. It is scummy, however it’s additionally what powers the chatbots so many people have began utilizing over the previous two and a half years.
The net is not giving up with out a struggle
However simply because the scenario is a bit dire for the web at giant, that does not imply its giving up completely. Quite the opposite, there may be actual opposition to any such observe, particularly when it goes after the little man.
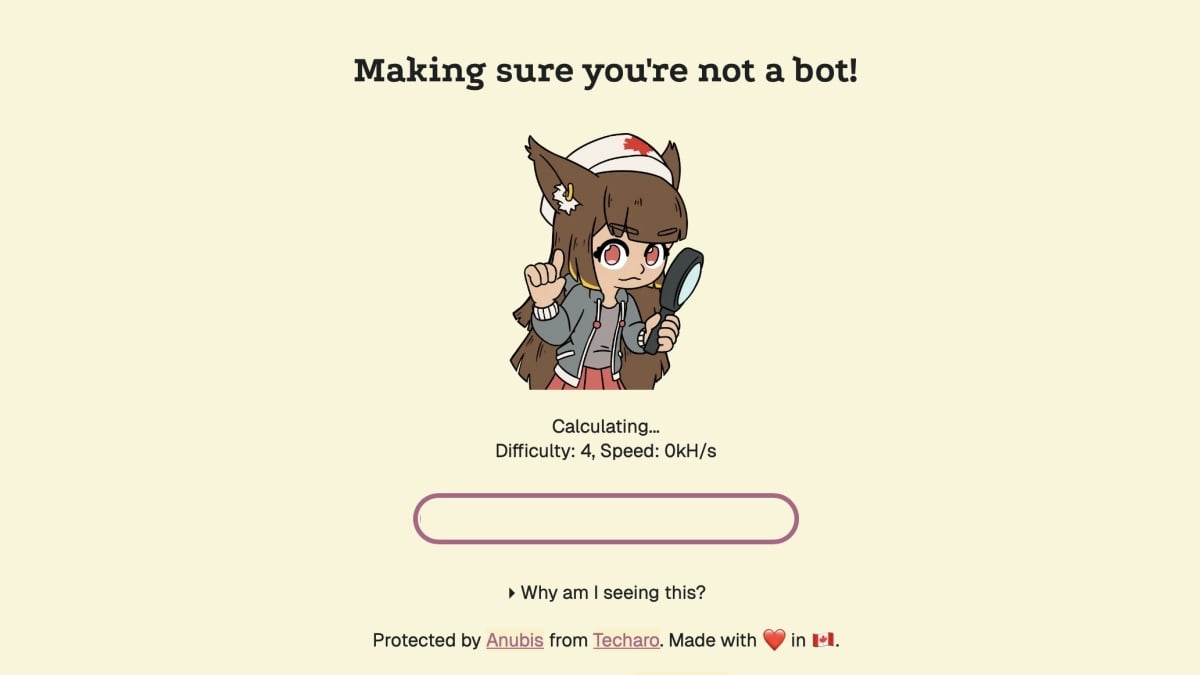
In true David-and-Goliath vogue, one net developer has taken it upon themselves to construct a instrument for net builders to dam AI bots from scraping their websites for coaching information. The instrument, Anubis, launched firstly of this yr, and has been downloaded over 200,000 instances.
Anubis is the creation of Xe Iaso, a developer primarily based out of Ottawa, CA. As reported by 404 Media, Iaso began Anubis after she found an Amazon bot clicking on each hyperlink on her Git server. After deciding in opposition to taking down the Git server completely, she experimented with a couple of completely different ways earlier than discovering a approach to block these bots completely: an “uncaptcha,” as Iaso calls it.
What do you assume up to now?
Here is the way it works: When working Anubis in your web site, this system checks {that a} new customer is definitely a human by having the browser run cryptographic math with JavaScript. In accordance with 404 Media, most browsers since 2022 can move this check, as these browsers have instruments built-in to run any such JavaScript. Bots, however, normally must be coded to run this cryptographic math, which might be too taxing to implement on all bot scrapes en masse. As such, Iaso has discovered a intelligent approach to confirm browsers through a check these browsers move of their digital sleep, whereas blocking out bots whose builders cannot afford the processing energy required to move the check.
This is not one thing the final net surfer wants to consider. As an alternative, Anubis is made for the individuals who run web sites and servers of their very own. To that time, the instrument is completely free and open supply, and is in continued growth. Iaso tells 404 Media that whereas she does not have the sources to work on Anubis full time, she is planning to replace the instrument with new options. That features a new check that does not push the end-user’s CPU as a lot, in addition to one that does not depend on JavaScript, as some customers disable JavaScript as a privateness measure.
If you happen to’re inquisitive about working Anubis by yourself server, you’ll find detailed directions for doing so on Iaso’s GitHub web page. You too can check your individual browser to be sure you aren’t a bot.
Iaso is not the one one on the net combating again in opposition to AI crawlers. Cloudflare, for instance, is blocking AI crawlers by default as of this month, and also will let prospects cost AI corporations that need to harvest the information on their websites. Maybe because it turns into simpler to cease AI corporations from overtly scraping the online, these corporations will cut back their efforts—or, on the very least, supply web site house owners extra in return for his or her information.
My hope is that I run into extra web sites that originally load with the Anubis splash display screen. If I click on a hyperlink, and am introduced with the “Ensuring you are not a bot” message, I am going to know that web site has efficiently blocked these AI crawlers. For some time there, the AI machine felt unstoppable. Now, it looks like there’s one thing we will do to a minimum of put it in verify.



